Quality Patent Searches With LexisNexis TotalPatent One®

It may sound outlandish but constructing and executing quality patent searches has a lot in common with erecting any physical structure. It is best to begin with a solid foundation in either scenario but, in the case of patent searches, the foundation’s quality depends on the number and type of prior art records that are accessible by a patent searcher. After the foundation is set, attention shifts to the details as the structure or patent search results emerge. When the building or searching phase appears to be complete, there must be methods for ensuring the quality of the project and assuring that no important details went overlooked. And finally, the ease with which a project is completed depends greatly on the tools and materials that are used—the LexisNexis TotalPatent One® patent search platform enables users to build top-quality patent searches quickly and effectively from the ground up.
Quality patent searches step 1: build a better search query
Patentability depends on prior art, which includes any published patent document from anywhere on the planet, which is why TotalPatent One® provides users with access to millions of full-text patent documents (approximately 70 terabytes of patent data) from a single search platform. However, while the foundation of patent records used to conduct a patent search must be broad enough to encompass any patent records that are material to the search, it should not be so broad that the volume of patent records is unmanageable. TotalPatent One users can intuitively find ways to tailor their patent search queries for focused search results based on keywords, classification codes, ownership information and more.
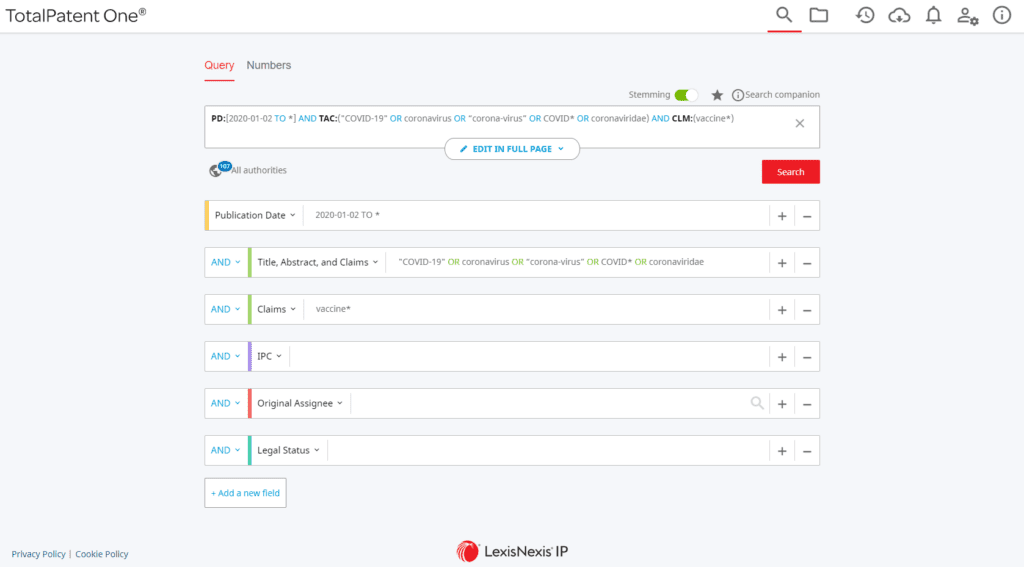
Quality patent searches step 2: identify material patent records
No matter how tailored a patent search query is, the resulting patent records will always be a mix of material and immaterial patent documents. It is a patent searcher’s responsibility to identify which of the resulting patent records are pertinent, and to isolate those records from the rest. One problem with most patent search platforms is that patent search results are presented as text-only lists of patent titles and patent document numbers. Because little can be determined from such information, researchers must take additional time and extra steps to access and review each patent document individually. By comparison, TotalPatent One helps researchers save time by providing important details about each patent search result in a convenient sidebar on the search results page. Patent summaries, image previews, claims and other important information reside within reach of patent professionals so they can make quick determinations about which patent records matter to their cases.
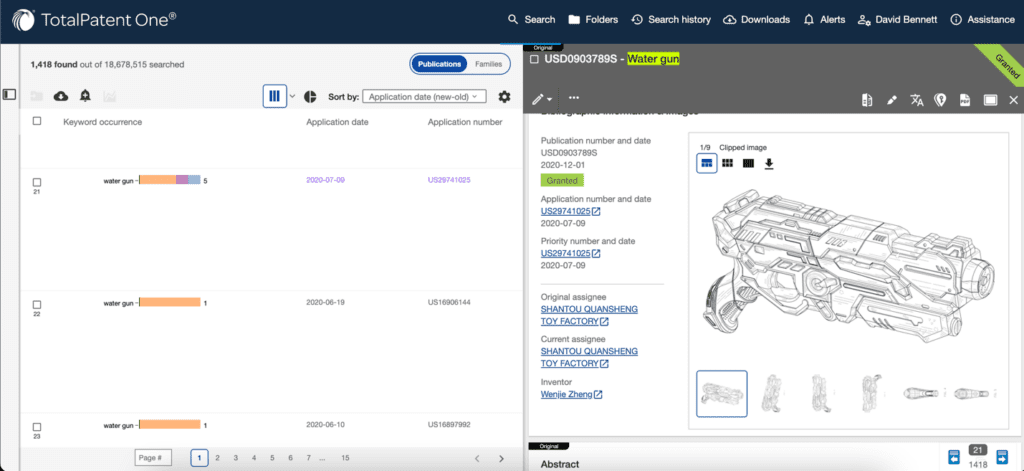
Quality patent searches step 3: find new leads through citations
You ran your query and you identified material records, but how certain are you that nothing was missed? One good way to double-check your results is to tackle the search from a different angle; rather than run another query, take a look at the patent records that relate to the material patent records that have already been identified. When viewing a patent or patent application in TotalPatent One, users can easily access the other global patent documents that make up a document’s patent family. Users can also navigate easily to backward-cited patent documents (related patent records that precede a document) as well as forward citations (later-filed patent records that cite the record being viewed). As a result, TotalPatent One users can work their way through a network of related references to bring closure to the patent search process.
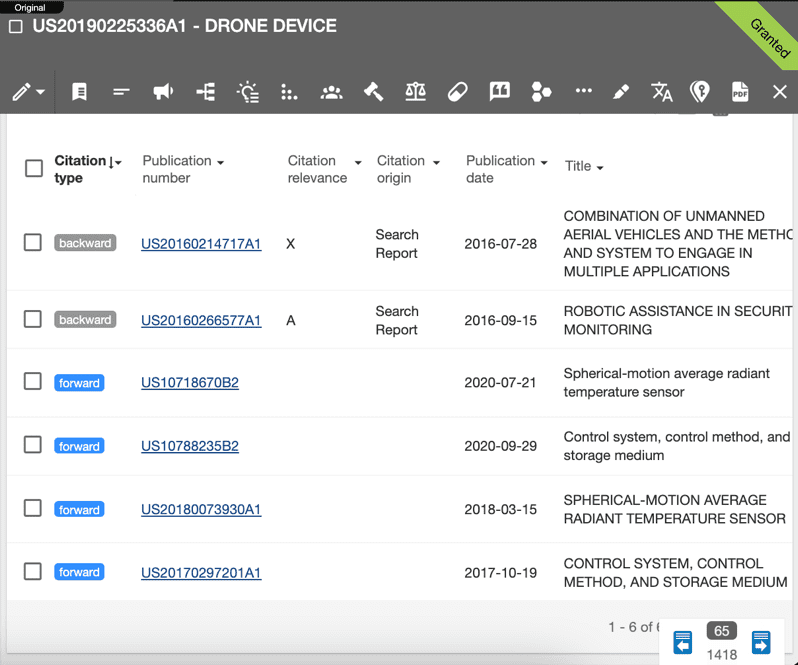
Start with a solid foundation, work out the details and double-check your work. The LexisNexis TotalPatent One patent search platform provides patent professionals with the patent data and search tools they need to build quality patent searches from the ground up.
Learn more about TotalPatent One.
Review TotalPatent One enhancements here and learn about the new search experience here.

Need to simplify your patent search?
Get quick, precise, and reliable results with full-text documents and high-resolution images from global patent authorities.