Combining Tools for All Stages of Patent Prosecution

Research, drafting and prosecution are the three cornerstones of the patent process. How a patent professional approaches each cornerstone can have a significant impact on the expenses, durations and outcomes of their patent applications. Many tools have been developed to help patent professionals perform their duties better and faster but combining tools at all stages of patent prosecution allows professionals to maximize their effectiveness against USPTO examiners for even greater success.
Research with LexisNexis TotalPatent One® and LexisNexis PatentAdvisor®
As any patent professional will tell you, research is normally the first of the stages of patent prosecution and the backbone of any good patent application.
Research not only helps determine the patentability of an invention and inform on how to best draft a patent application, but it also sheds light on how rocky the patent process is likely to be. Patentability can be affected by prior art that exists anywhere in the world, which is why the TotalPatent One® patent search platform allows users to search and efficiently filter through over 100 million patent records from over 100 worldwide patent authorities. When paired with the PatentAdvisor™ patent analytics platform, patent professionals can also identify which USPTO art units are most likely to evaluate their applications. PatentAdvisor patent analytics then reveal which potential art units are the most statistically favorable, and patent analytics help determine how difficult patent prosecution will likely be and how long it will likely take.
Drafting With PatentAdvisor and LexisNexisPatentOptimizer®
In the second of the stages of patent prosecution and armed with the information gained from TotalPatent One search results and PatentAdvisor patent analytics, patent professionals can approach their application drafting strategically. Knowledge gained from thorough research helps minimize the likelihood of Section 102 novelty rejections or Section 103 obviousness rejections, and the risks and limitations revealed by prior art references help shape a patent application’s structure, terminology and scope.
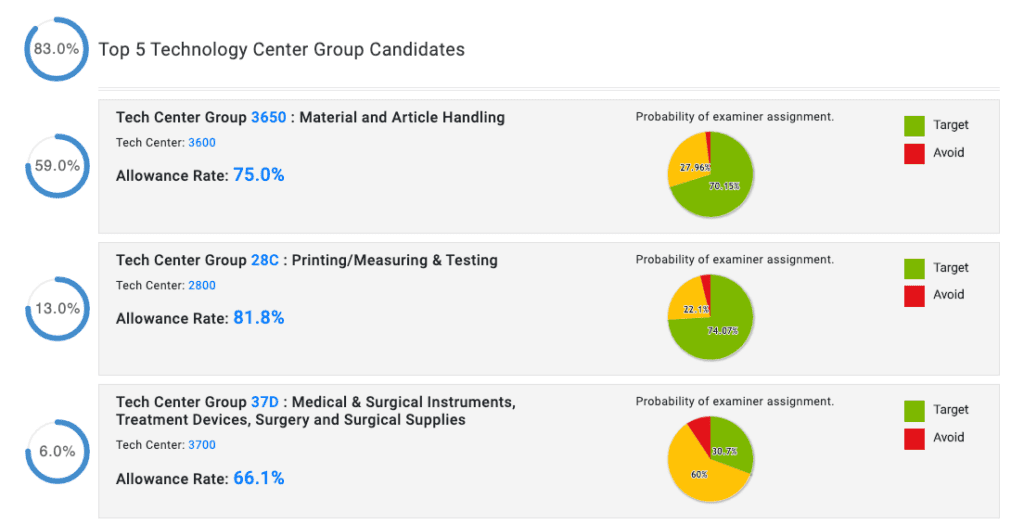
After using PatentAdvisor and the Tech Center Navigator (formerly PathWays™) tool to identify which of the potential art units is the most applicant-friendly, the Tech Center Navigator suggests the words and phrases a drafter should include or avoid to improve their chances of having their patent application assigned to the art unit they are targeting. Once a patent practitioner has a draft of their art unit-specific patent application, they can rely on the PatentOptimizer® patent drafting tool to run a comprehensive review for drafting errors and inconsistencies, as well as other issues that could potentially lead to examiner objections or Section 112 rejections. PatentOptimizer can even automatically generate complete Information Disclosure Statements based on the content in a patent application draft, to help save practitioners additional time and effort.
Patent prosecution with PatentAdvisor and PatentOptimizer
Once a patent application has been filed and assigned to a USPTO examiner, the focus of a patent prosecution strategy shifts to anticipating the patent examiner’s behavior, taking action to proactively avoid delays and unnecessary prosecution expenses, and responding effectively and efficiently to examiner objections and rejections. The PatentAdvisor patent prosecution tool is a patent professionals command center for making predictions about their assigned examiners using USPTO statistics and analytics. PatentAdvisor uses USPTO patent examiner patent prosecution data to help identify trends and patterns in examiner behavior to help patent professionals develop more effective prosecution strategies, better assess prosecution risks, help clients budget more effectively and more accurately predict how long an application will remain pending before resolution.
PatentAdvisor can help users identify actions they can take to avoid office actions and prosecute more efficiently, however not all office actions are avoidable. When a patent application is rejected by a patent examiner, the PatentOptimizer Office Action Response (OAR) tool can help users develop rebuttals to successfully overcome the rejection. By tapping into USPTO patent records and evaluating the rejection that is being faced, the OAR tool can identify arguments that have been successful against similar rejections in previously prosecuted patent applications. Users can then use the OAR tool to generate a response draft that includes arguments that have been tried and proven.
Research, drafting and prosecution are the cornerstones of the patent process, and TotalPatent One, PatentAdvisor and PatentOptimizer make up the foundation of optimal patent strategies. Users who leverage multiple tools at each of the stages of patent prosecution yield better results throughout the patent process. With more information and insight, patent professionals can navigate the patent process with fewer obstacles and better outcomes.
PatentAdvisor provides exclusive patent analysis tools for successful patent prosecution. Learn more by reading Patent Prosecution Analytics: No Longer Just a Nice to Have and watching the on-demand webinar.
Gain insight into your application’s future to help you develop data-driven filing strategies with the Tech Center Navigator.
Learn more by reading Strategic Drafting With Patent Analytics Tools.
Get guidance on how to write a patent application of optimal quality with PatentOptimizer.